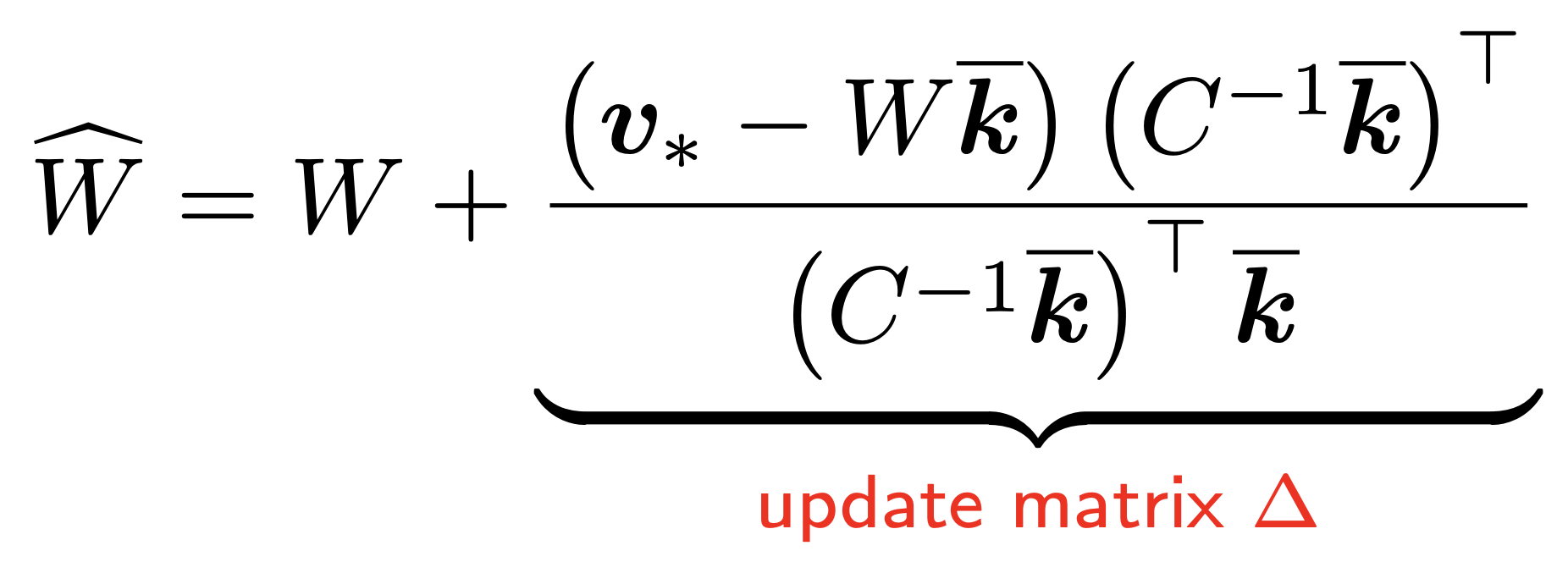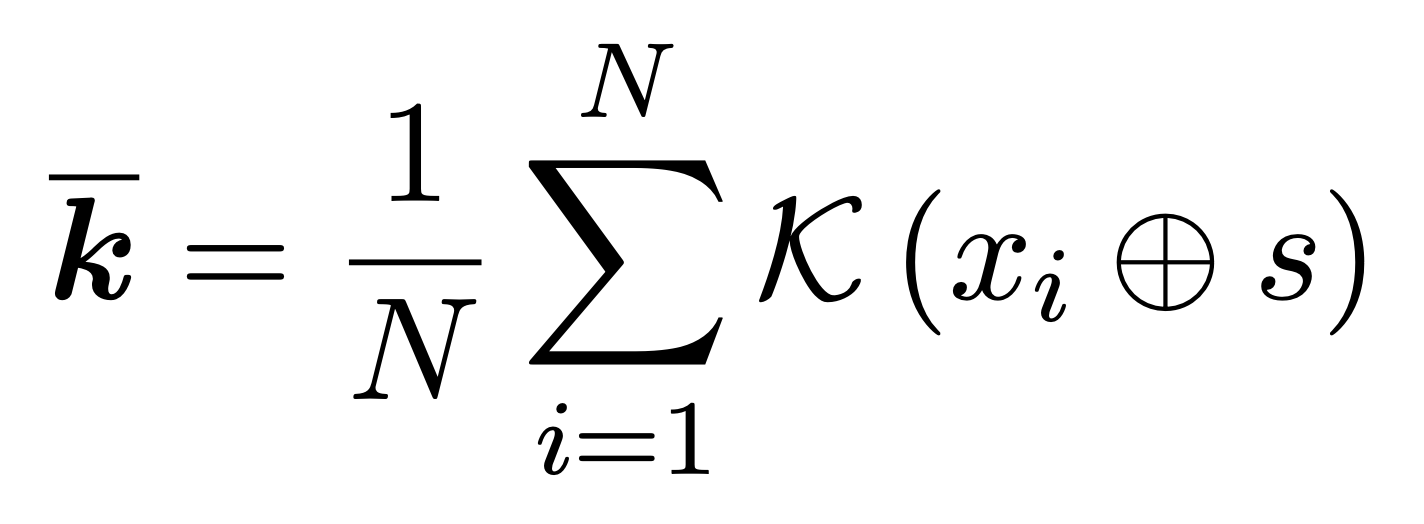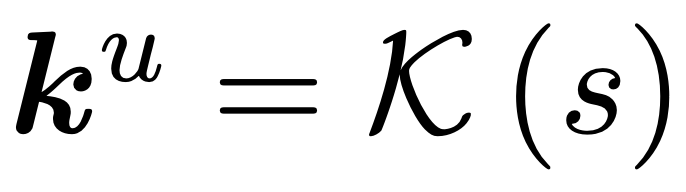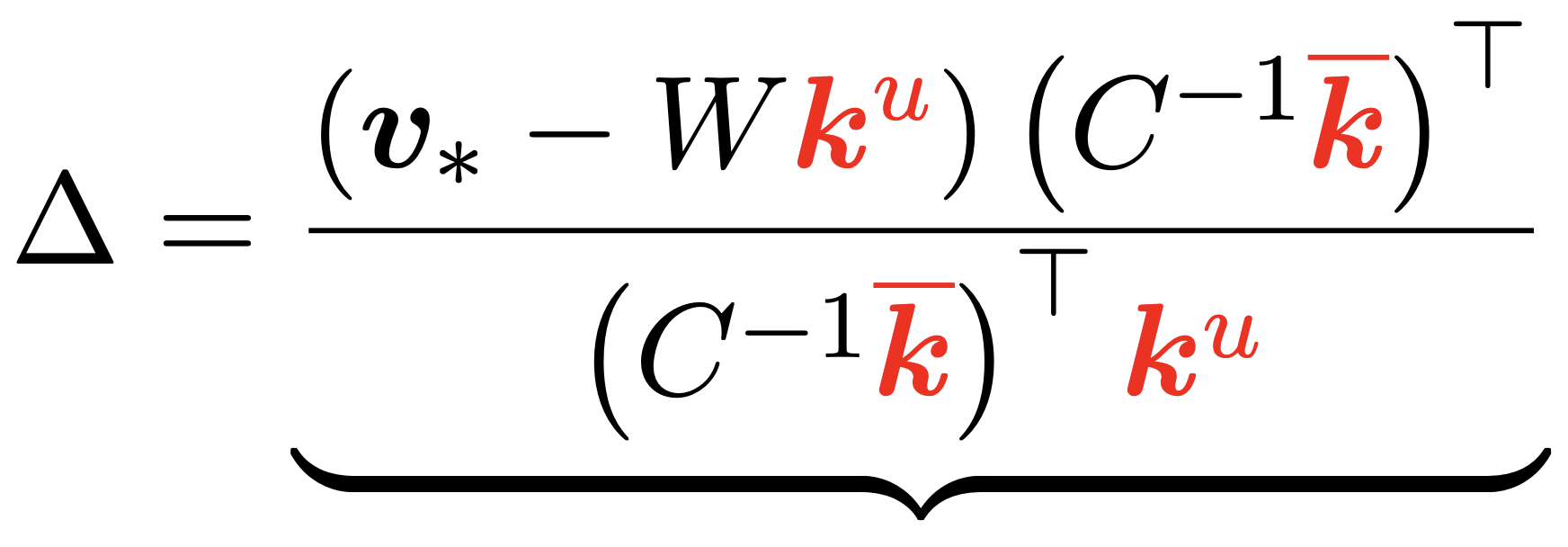BibTeX
@inproceedings{yang-etal-2024-butterfly,
title = "The Butterfly Effect of Model Editing: Few Edits Can Trigger Large Language Models Collapse",
author = "Yang, Wanli and
Sun, Fei and
Ma, Xinyu and
Liu, Xun and
Yin, Dawei and
Cheng, Xueqi",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand and virtual meeting",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.322",
pages = "5419--5437",
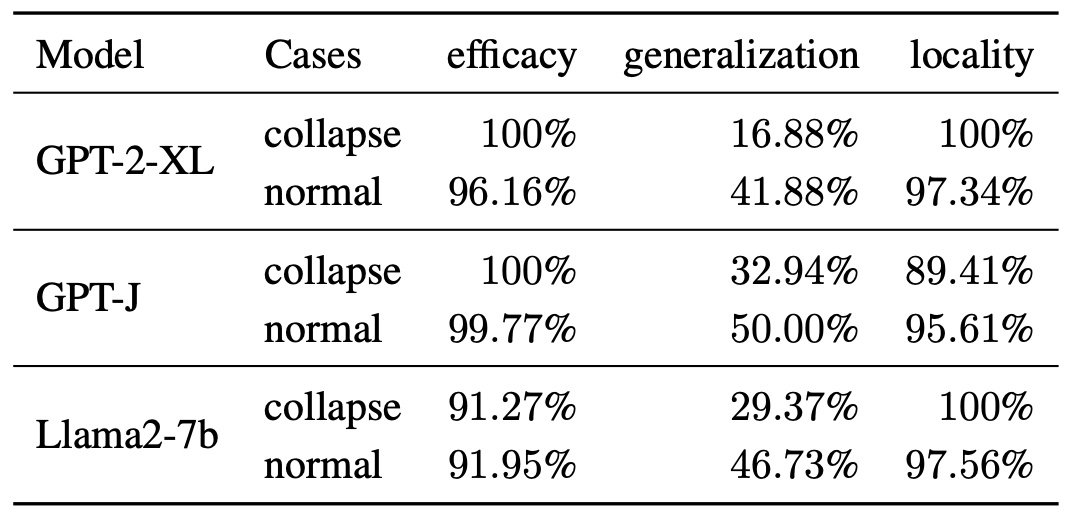
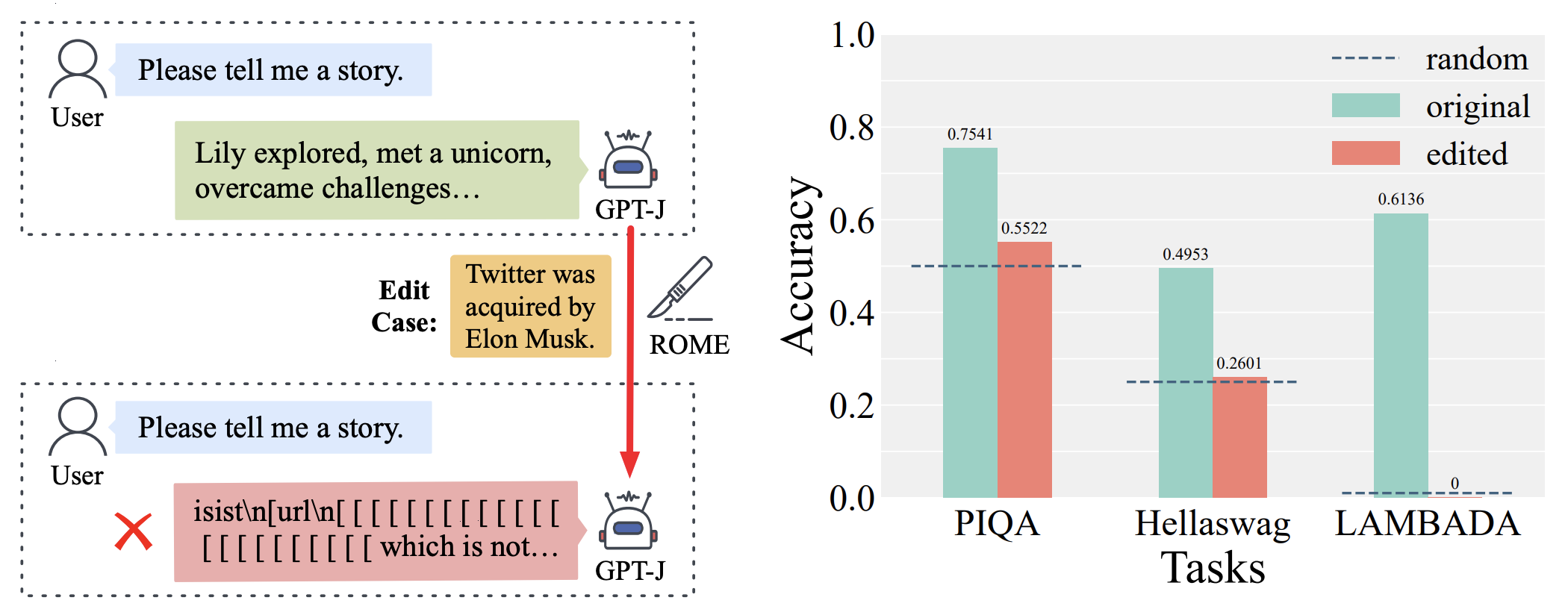
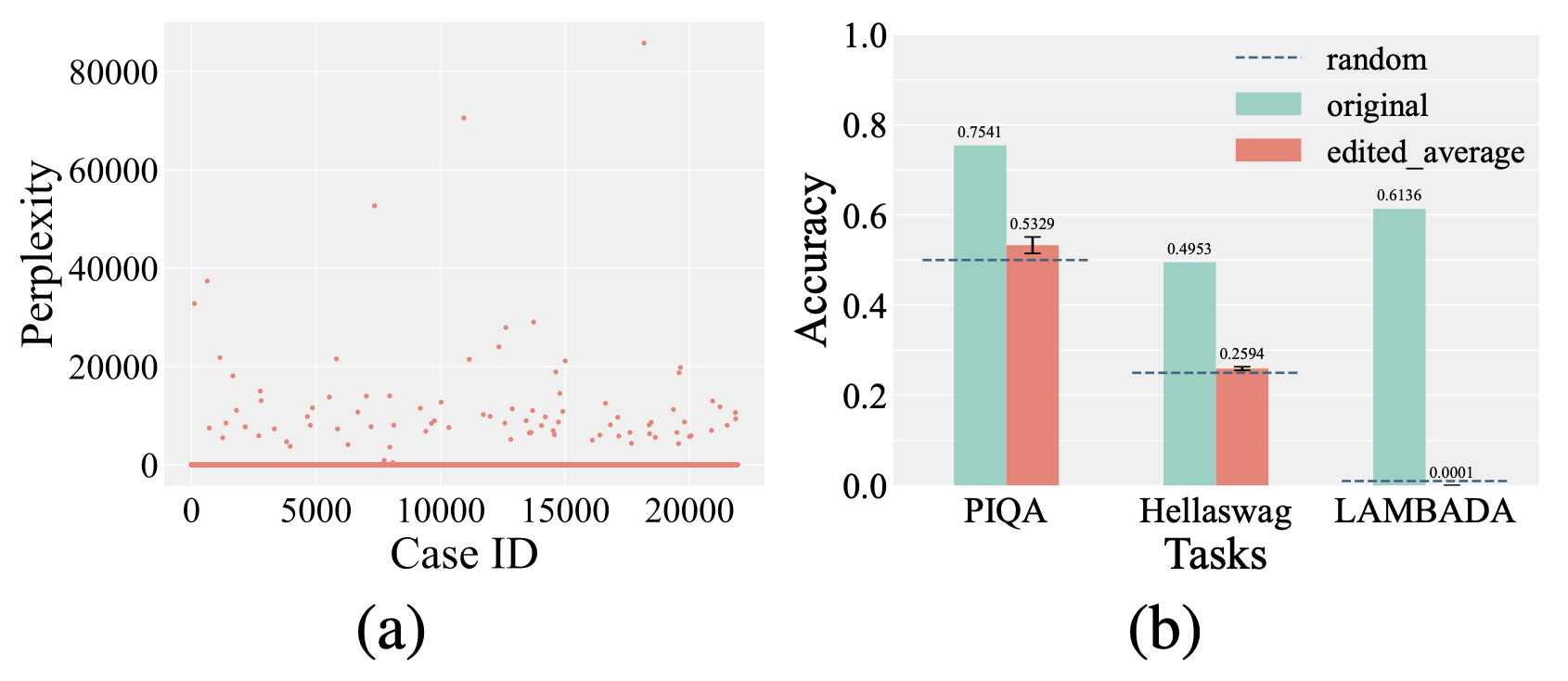
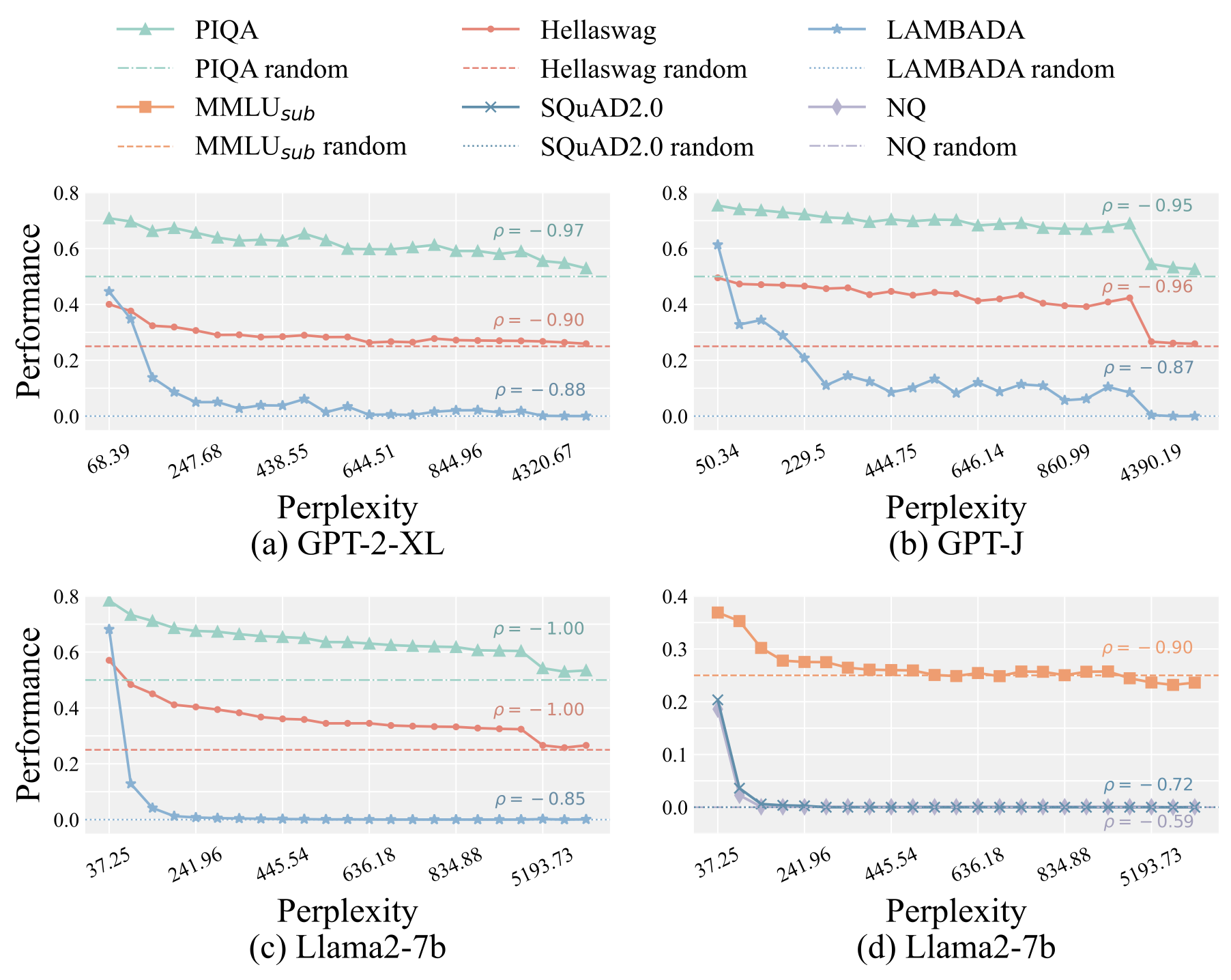
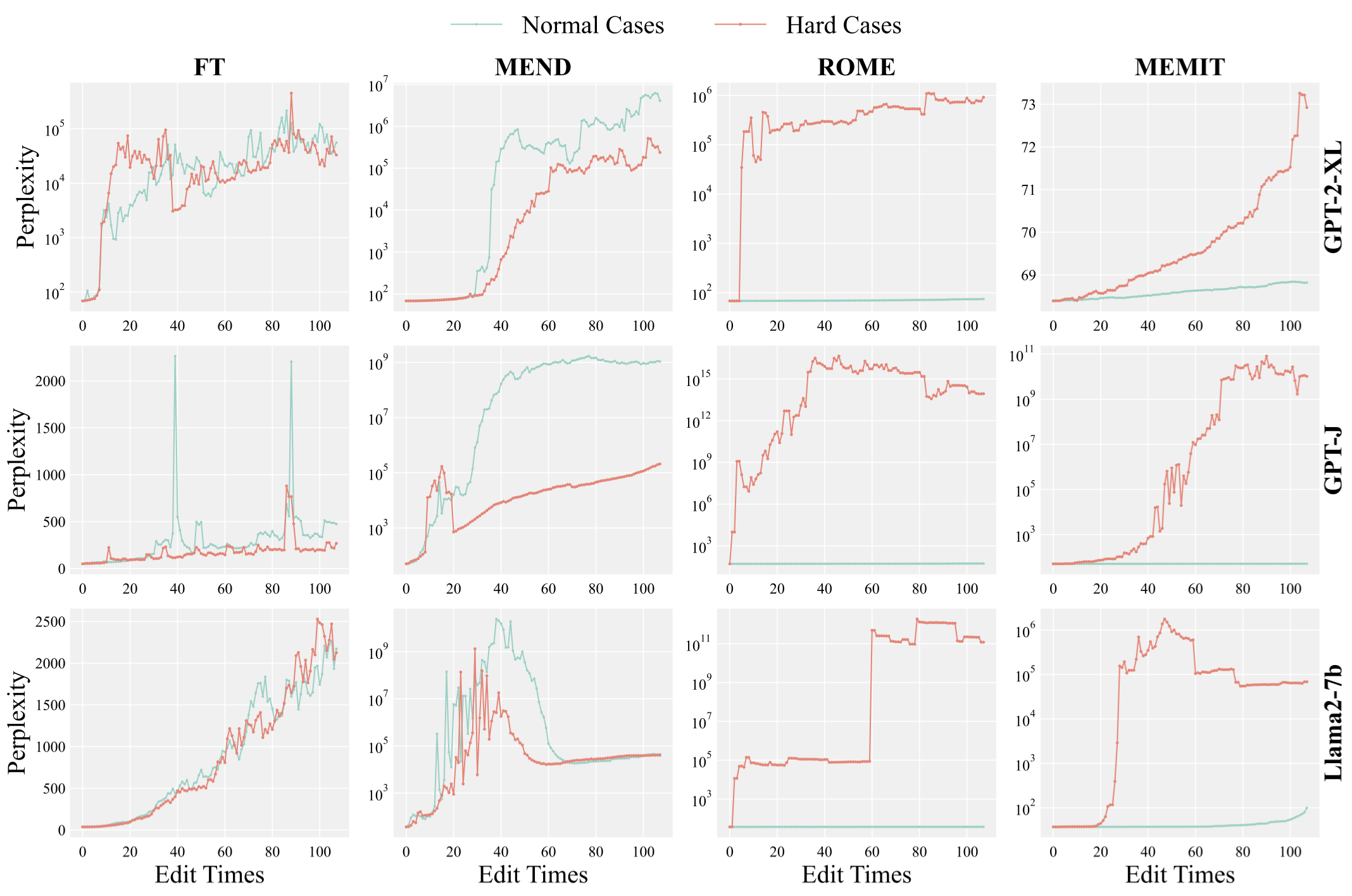
abstract = "Although model editing has shown promise in revising knowledge in Large Language Models (LLMs), its impact on the inherent capabilities of LLMs is often overlooked. In this work, we reveal a critical phenomenon: even a single edit can trigger model collapse, manifesting as significant performance degradation in various benchmark tasks. However, benchmarking LLMs after each edit, while necessary to prevent such collapses, is impractically time-consuming and resource-intensive. To mitigate this, we propose using perplexity as a surrogate metric, validated by extensive experiments demonstrating changes in an edited model{'}s perplexity are strongly correlated with its downstream task performances. We further conduct an in-depth study on sequential editing, a practical setting for real-world scenarios, across various editing methods and LLMs, focusing on hard cases from our previous single edit studies. The results indicate that nearly all examined editing methods result in model collapse after only few edits. To facilitate further research, we have utilized GPT-3.5 to develop a new dataset, HardEdit, based on those hard cases. This dataset aims to establish the foundation for pioneering research in reliable model editing and the mechanisms underlying editing-induced model collapse. We hope this work can draw the community{'}s attention to the potential risks inherent in model editing practices.",
}
@inproceedings{yang-etal-2024-fall,
title = "The Fall of {ROME}: Understanding the Collapse of {LLM}s in Model Editing",
author = "Yang, Wanli and
Sun, Fei and
Tan, Jiajun and
Ma, Xinyu and
Su, Du and
Yin, Dawei and
Shen, Huawei",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.236",
doi = "10.18653/v1/2024.findings-emnlp.236",
pages = "4079--4087",
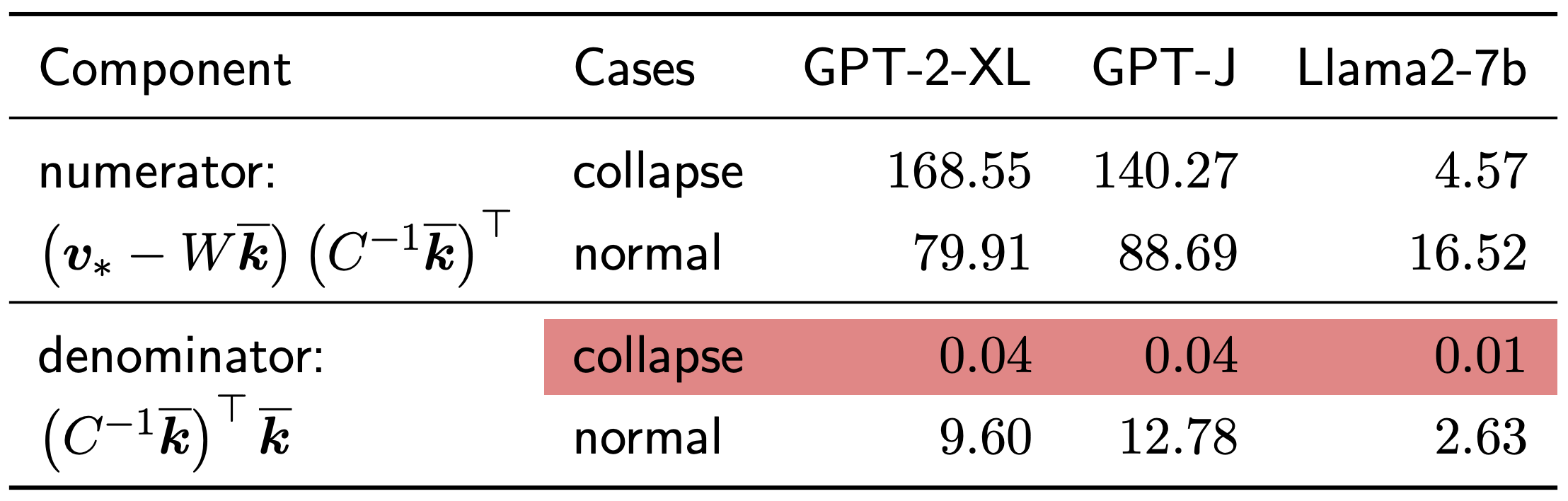
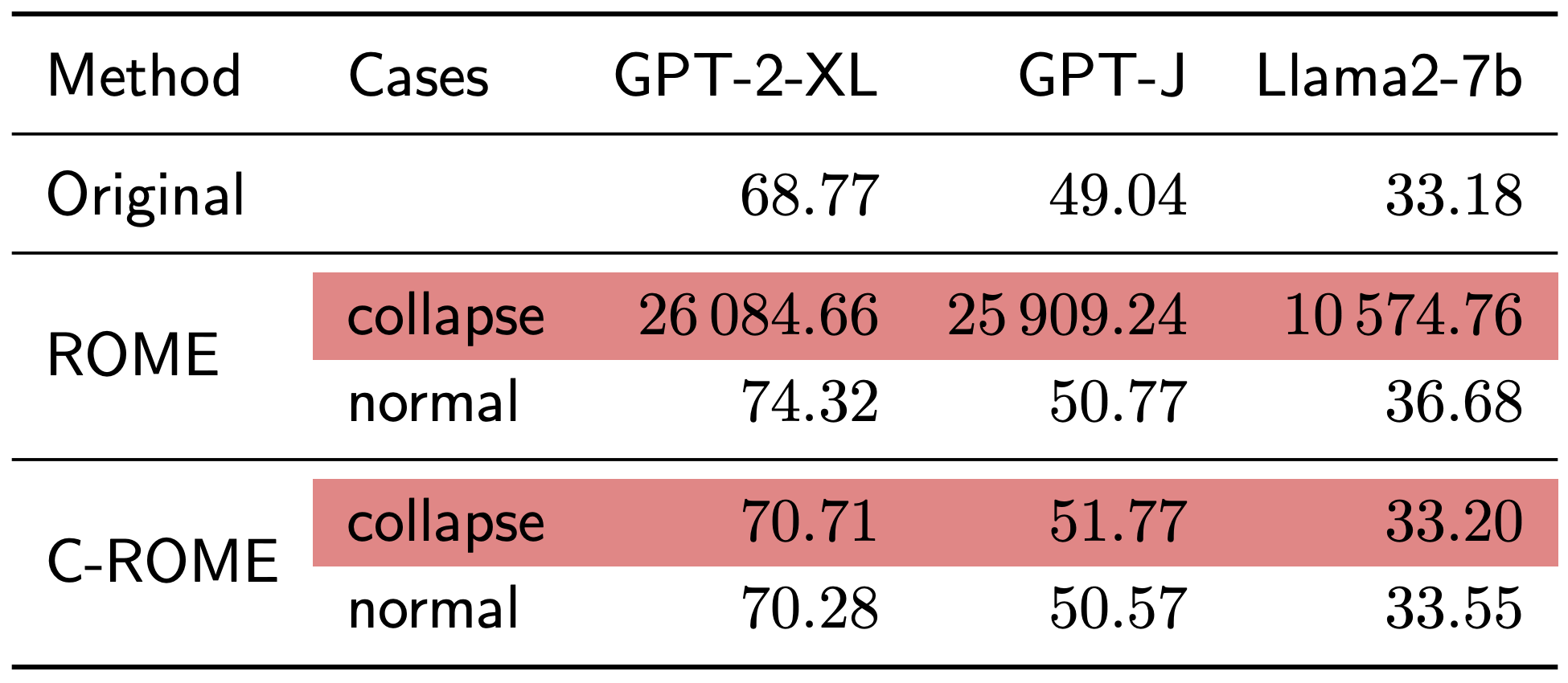
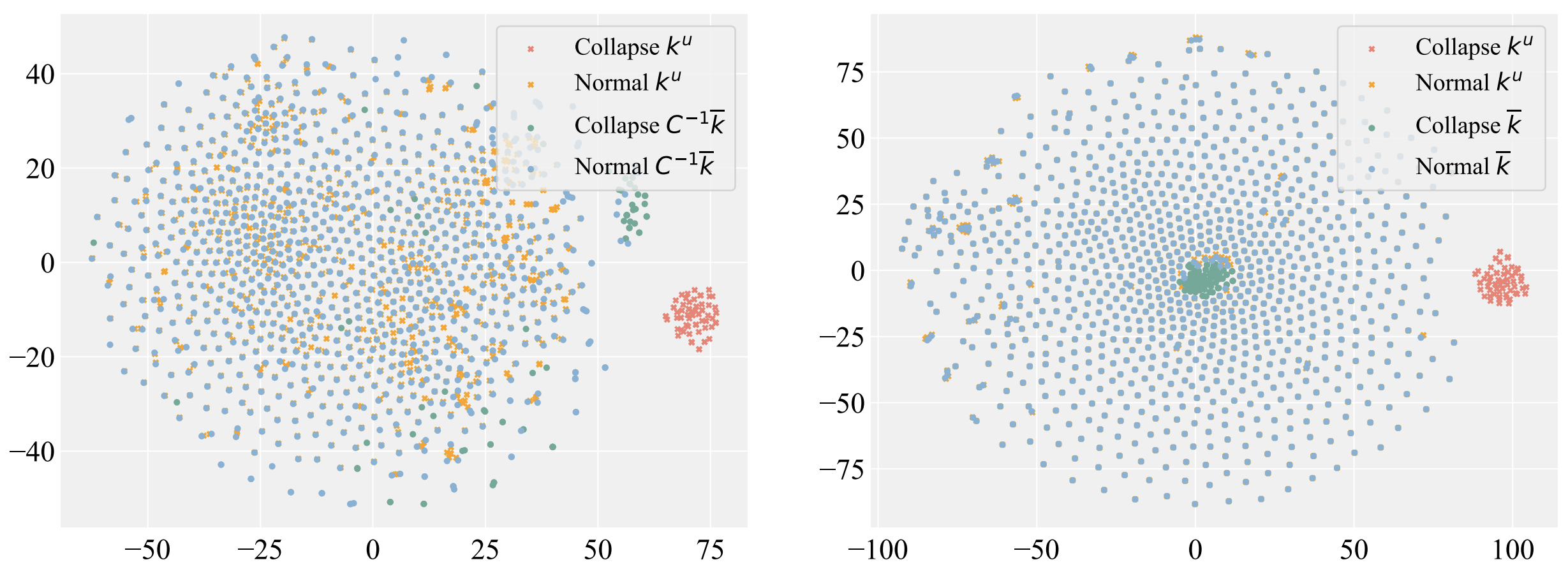
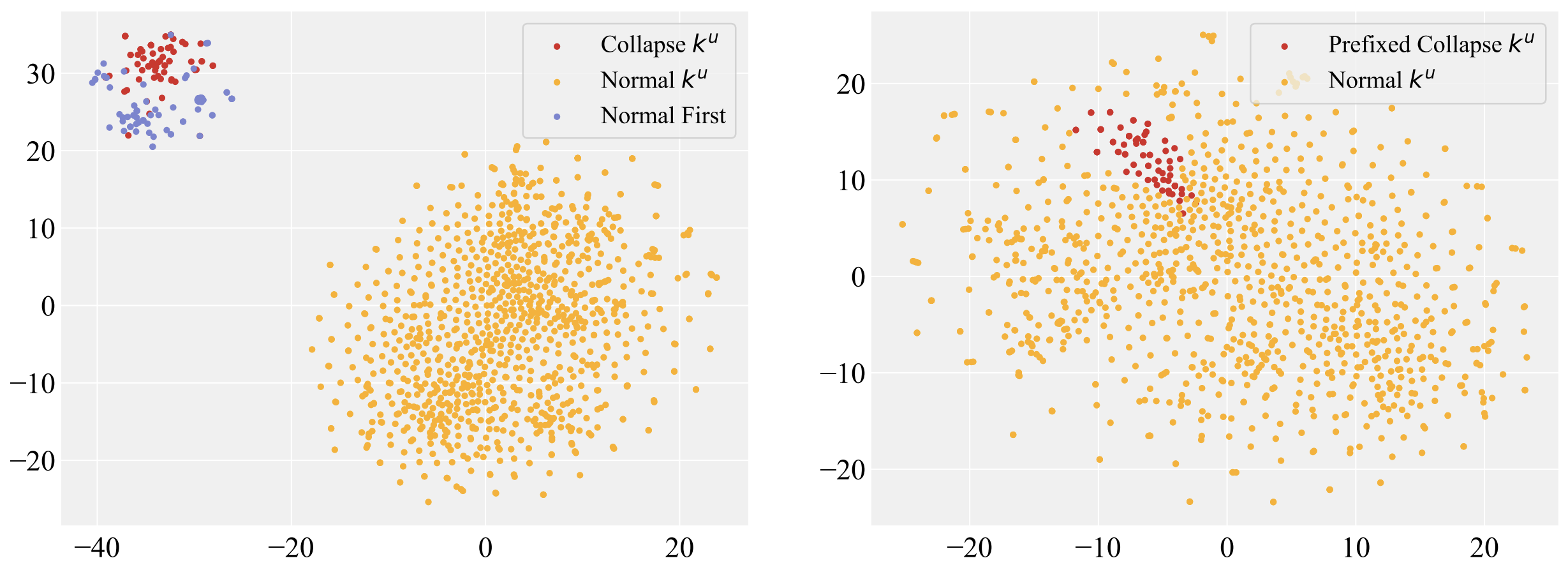
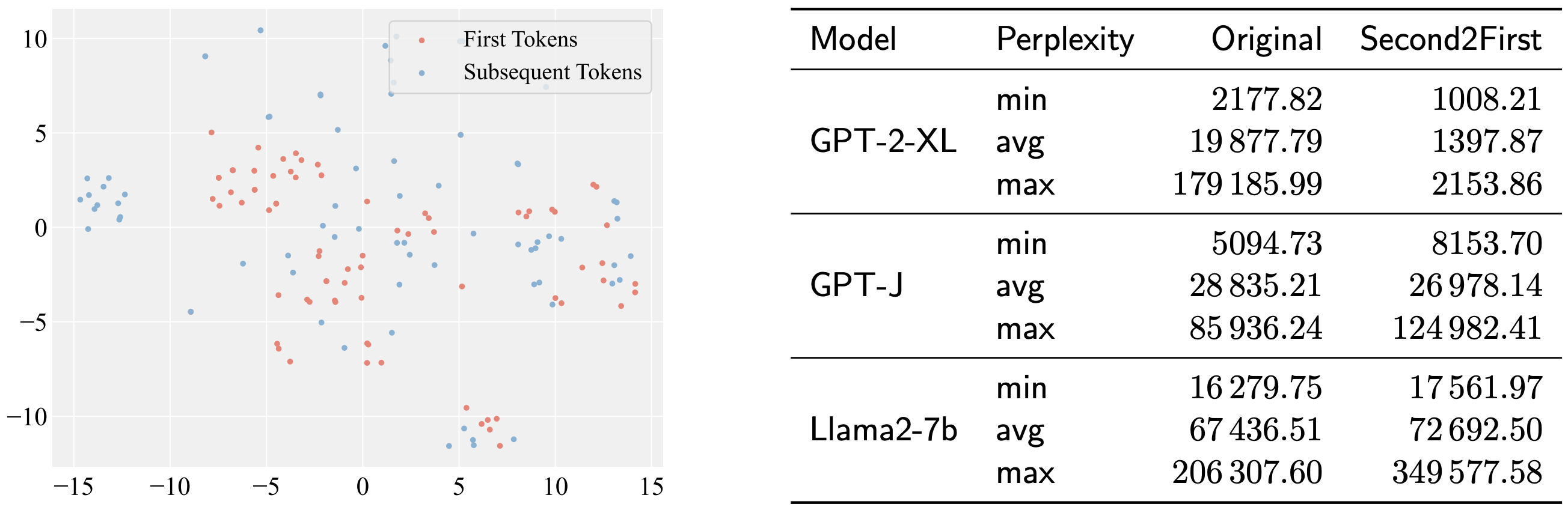
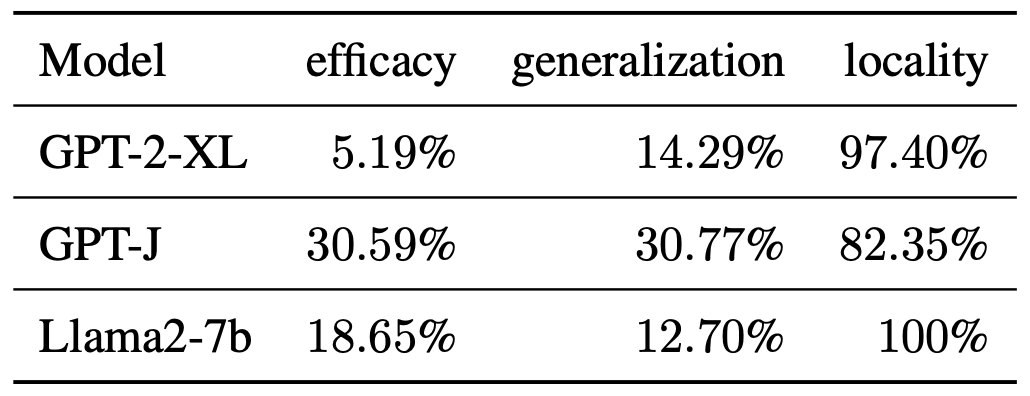
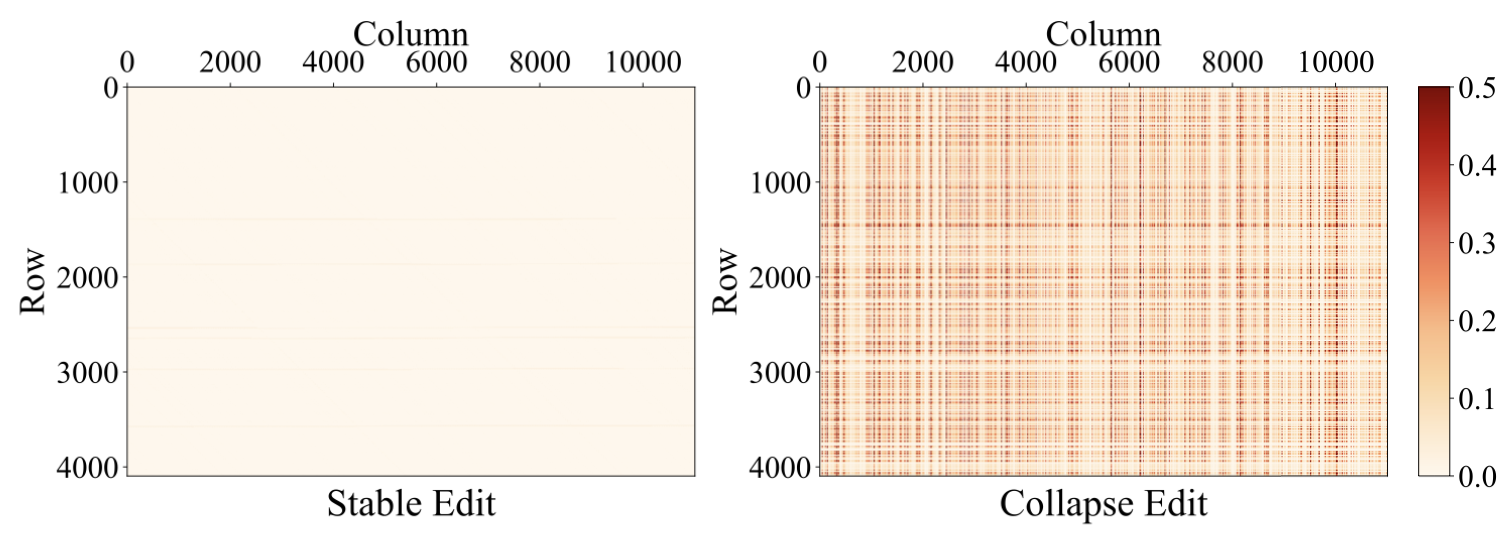
abstract = "Despite significant progress in model editing methods, their application in real-world scenarios remains challenging as they often cause large language models (LLMs) to collapse. Among them, ROME is particularly concerning, as it could disrupt LLMs with only a single edit. In this paper, we study the root causes of such collapse. Through extensive analysis, we identify two primary factors that contribute to the collapse: i) inconsistent handling of prefixed and unprefixed keys in the parameter update equation may result in very small denominators, causing excessively large parameter updates; ii) the subject of collapse cases is usually the first token, whose unprefixed key distribution significantly differs from the prefixed key distribution in autoregressive transformers, causing the aforementioned issue to materialize. To validate our findings, we propose a simple yet effective approach: uniformly using prefixed keys during editing phase and adding prefixes during testing phase to ensure the consistency between training and testing. The experimental results show that the proposed solution can prevent model collapse while maintaining the effectiveness of the edits.",
}

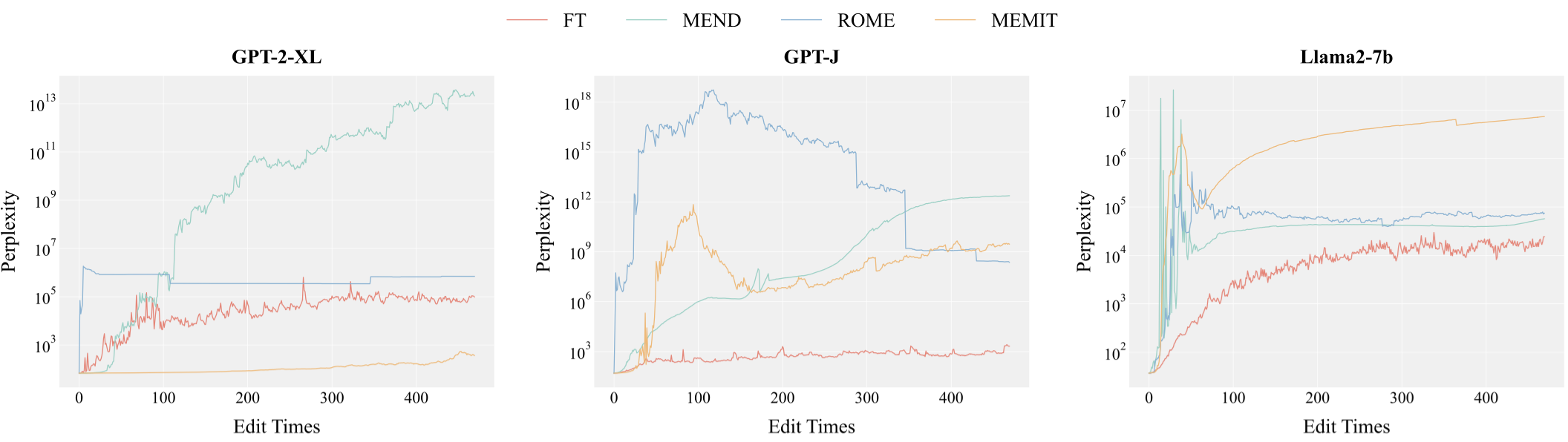
 The Fall of ROME :
The Fall of ROME :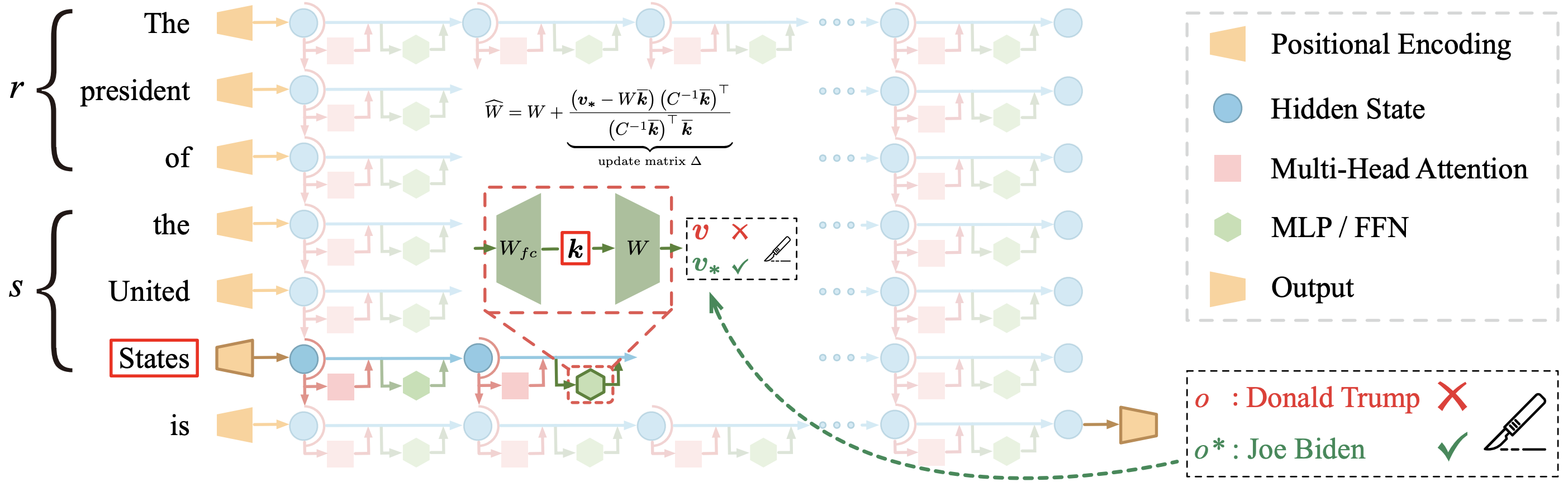
 Why is the update matrix so large?
Why is the update matrix so large?